
킹머핀의 제작 일지
인공신경망과 경사하강법 그리고 직선의 방정식 본문
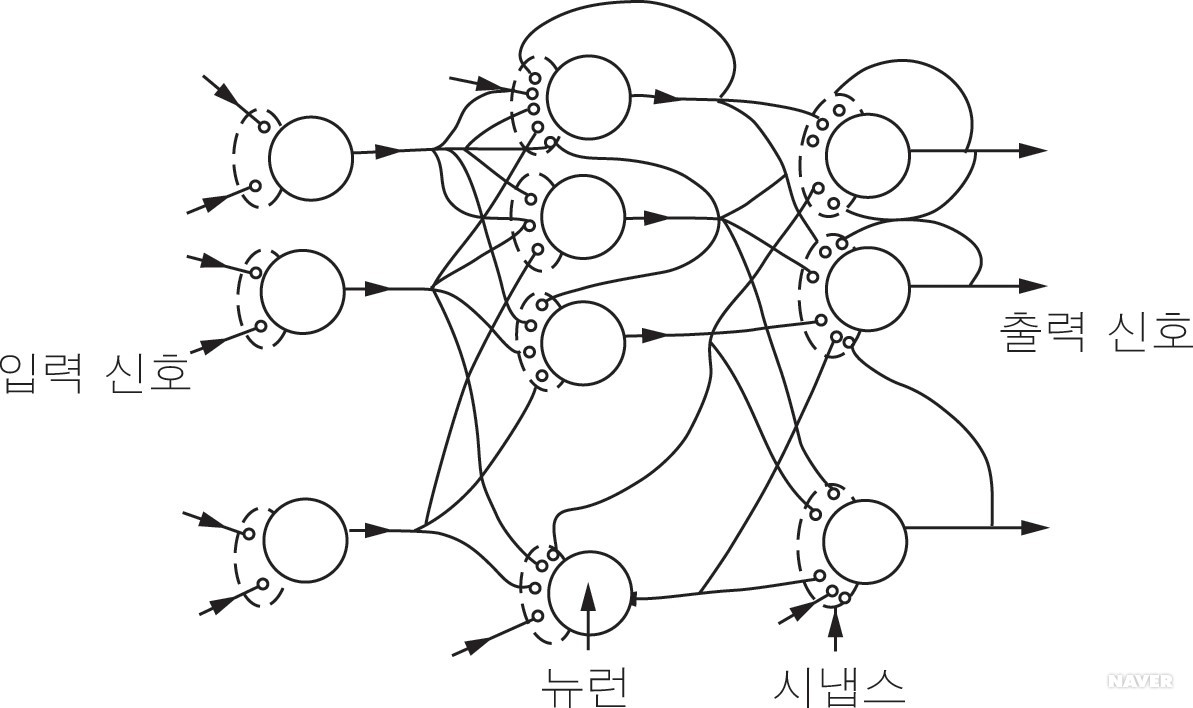
강의 들으면서 정리하는 거라 내용이 완전하지 않음.

대충 인터넷 뒤져보았을 때 인공신경망을 가장 쉽게 설명하는 위의 이미지. 신경망 그림에는 없지만, 서로 이어져있는 신경세포의 시냅스는 아래와 같이 사실 축삭말단과 수상돌기가 아주 약간 떨어져 있다.

축삭돌기의 말단인 축삭말단은 신경전달물질 주머니가 있고, 이 주머니에서 신경전달물질의 양을 조절한다. 위 그림에서는 축삭말단이 오른쪽에 있는 걸로 보아 오른쪽에서 왼쪽으로 신경전달 중인 듯. 혹시 몰라서 찾아봤더니, 역시 (화학적)시냅스는 한 방향으로만 이루어진다.
시냅스 | 인체정보 | 의료정보 | 건강정보 | 서울아산병원
뉴런이라는 신경세포의 부분 중 자극을 세포 밖으로 전도시키는 돌기인 축삭의 끝부분과 신경전달물질이 오가는 다음 뉴런 사이의 틈을 시냅스라고 합니다. 전신의 뉴런이 위치하는 곳에 분포�
m.amc.seoul.kr
이러한 신경망 구조를 인공신경망으로 표현했을 때, x는 시냅스 전 신경세포(input), w는 신경전달물질 양(weight)이다. x와 w를 곱한 모든 값을 더했을 때 기준치보다 크면 1, 아니면 0으로 변환한다(output). 수식으로 표현하면
\[ 𝜑(h = \sum w_{i}x_{i}) = y \]
(𝜑는 계단함수, 활성함수 종류 중 하나) 눈치가 빠른 사람이라면 y절편이 없는 직선의 연립방정식과 다르지 않다는 것을 알아챘을 것이다. 바로 나다.
변환한 값을 분류할 때, 기준치(역치)가 0이면 \( w_{i}x_{i} + w_{i}x_{i} = 0 \). 하지만 이 직선은 원점을 지나야 하기 때문에 두 값을 에러 없이 완벽하게 분류할 수 없다. 그래서 y절편(bias)을 더해주어 두 값을 오차 적게 분류하는 직선을 만든다. \( w_{i}x_{i} + w_{i}x_{i} + b = 0 \). 직선의 연립방정식과 똑같아졌다. 이 식에서 bias를 x가 1이고 w가 b인 시냅스(W)로 표현할 수 있다. 행렬식으로 표현하기 좋아졌지?
머신러닝 분류와 직선의 방정식
수업 들으면서 정리하는 거라 내용이 완전하지 않을 수 있음.Binary-Classification두 가지로 분류한 사...
blog.naver.com
활성함수는 계단함수보다는 위의 출처에서처럼 모든 구간에서 미분이 가능한 연속 함수인 시그모이드 함수를 사용할 수 있다. 이러한 방법으로 오차 적은 최적의 직선의 기울기(w)와 y절편(b, bias, 기준치)을 구하는 것을 퍼셉트론 학습이라고 한다.
\[ cost(w, b) = \frac{1}{m}\sum_1^m(H(x^{(i)}) - y^{(i)})^{2}, H(x) = 예측값 = wx + b \]
평균제곱오차(MSE)를 이용함. 물론 cost(비용)은 적을수록 좋음. 제곱했기 때문에 가장 낮은 오차는 0. (근데 왜 학습 데이터 레이블을 윗첨자로 표기했지? 맘대로 아랫첨자로 했다가 '시키는 대로' 윗첨자로 수정했다 ㅎㅎ)
머신러닝과 딥러닝, 데이터 분석과 직선의 방정식
강의명은 '가상현실응용'이지만 가상현실과 거의 관련없는 그냥 영상 분야 인공지능 + 파이선 강...
blog.naver.com
일단 b가 0이라고 하자. 그럼 \( cost(w) = \frac{1}{m}\sum_1^m(wx^{(i)} - y^{(i)})^{2} \) 에서 cost가 가장 낮은 w값을 어떻게 구하는가? 제곱을 했으니, 최솟값을 갖는(아래로 볼록한) 2차원 그래프가 그려질 것이다. 그 그래프에서 기울기가 0인 w값이 최솟값일 것이다. 그럼 기울기가 0에 가까운 w값은 어떻게 구하는가?

경사하강법 : 함수의 기울기(경사)를 구하고 경사의 절댓값이 낮은 쪽으로 계속 이동시켜 극값에 이를 때까지 반복시키는 것이다.
\[ w = w - 반영비율 \times 기울기 = w - \alpha \times \frac{\partial}{\partial w}cost(w) \]
\[ = w - \alpha \times \frac{1}{m}\sum_1^m(wx^{(i)} - y^{(i)})x^{(i)} \]
\[ cost(w) = \frac{1}{2m}\sum_1^m(wx^{(i)} - y^{(i)})^{2} \]
갑자기 cost(w)의 1/m 을 1/2m 으로 바꾼 이유는 \( \frac{\partial}{\partial w}cost(w) \) (미분)했을 때 곱하게 되는 값(2)을 단순히 그만큼 다시 나누어준 듯. 생각해보니 이렇게 임의로 수를 더하든 곱하든 간에 기울기가 0에 가까운 w값만 찾으면 되네.
그래서 이 계산을 얼마나 반복해야 하는가?! 바로 w의 변화량이 0에 가까워질 때까지. 즉 \( \alpha \times \frac{1}{m}\sum_1^m(wx^{(i)} - y^{(i)})x^{(i)} \) (기울기)가 0에 가까워질 때까지. 그렇게 찾은 w로 y = wx 학습모델을 만들 수 있다.
𝛼(반영비율, 상수)는 학습률. 학습률이 작으면 cost가 0인 w값에 한 번씩 다가가는 폭이 좁아서 학습 속도가 느리다. 반대로 학습률이 크면 폭이 넓어서 학습 속도는 빠르지만 cost가 0인 w값을 너무 지나칠 수 있다! 그래서 이 적당한 학습률을 찾는 것이 중요하다. 보통은 0.01 또는 0.001을 사용한다. 계산해서 찾는 방법도 있다는데 그건 일단 PASS.
학습률은 엔트리 인공지능에서도 다루어본 적이 있다. 이 글이 엔트리 카테고리에 있는데, 드디어 처음으로 연관된 내용을 배웠다! ㅎㅎ
사탕 나무야 열려라!
왜 사탕이 자라는 나무는 없을까?혹시 간절히 바라면 이루어주지 않을까!나무님.. 제발 사탕 열매를 맺어...
blog.naver.com
이제 아까 일단 0으로 했던 b를 다시 깨워보자. 그럼 최솟값을 갖는(아래로 볼록한) 3차원 그래프가 그려질 것이다. 기울기가 0에 가까워지는 b도 찾아야 하니 축이 하나 더 생긴 셈. 그래봤자 같은 경사하강법으로 w와 b를 찾을 수 있다. 이 때 편미분(다변수 함수의 특정 변수를 제외한 나머지 변수를 상수로 생각하여 미분하는 것)을 사용한다.
샘플도 여러 개 가져와보자. 식을
\[ y = 𝜑(\sum_1^n(w_ix_i + b)) \]
\[ cost = \frac{1}{2}\sum_{k = 1}^m(d_k - y_k)^2 \]
\[ w_i = w_i + \alpha\times\sum_{k=1}^m(d_k - y_k)x_i \]
\[ = w_i - \alpha\times\sum_{k=1}^m(y_k - d_k)x_i \]
이렇게 정의할 수 있다. cost(w, b) 계산에서 m을 나누지 않은 것은 비례상수(그냥 기울기인가?)이기 때문에 결과에 큰 영향이 없기 때문. \( d_k \) 는 레이블 데이터, 목적값.
...윗첨자로 표기하던 (i)는 왜 다시 아랫첨자로 바뀐 것이지? 이 들쭉날쭉함을 거부하고 싶지만, 일단은 참고 수업을 따라가기로 해 본다..
'엔트리 > 심화' 카테고리의 다른 글
| MacOS) 에서 아나콘다를 사용하지 마세요 (0) | 2021.03.24 |
|---|---|
| 코랩) Flask 로컬 서버 접속하는 법 (0) | 2021.03.13 |
| 다층신경망과 CNN (0) | 2020.11.03 |
| 단층신경망에서 다층신경망으로 (0) | 2020.10.25 |
| 머신 러닝과 파이선 (0) | 2020.10.13 |

